Projektuebersicht
StarVLA ist eine modulare Codebasis nach dem Baukastenprinzip zur Entwicklung von Vision-Language-Modellen (VLMs) zu Vision-Language-Action-Modellen (VLA).
Kurz gesagt: VLMs verstehen Bilder und Text; VLAs geben zusaetzlich Roboter-Aktionen aus. StarVLA uebernimmt diese Transformation durchgaengig — von der Datenvorbereitung ueber das Modelltraining bis zur Simulationsevaluation — mit Komponenten, die unabhaengig debuggbar und per Plug-and-Play einsetzbar sind.
Hauptmerkmale
Abschnitt betitelt „Hauptmerkmale“VLA-Frameworks
Abschnitt betitelt „VLA-Frameworks“StarVLA stellt offiziell die auf Qwen-VL basierende StarVLA-Modellfamilie mit 4 verschiedenen Aktionsausgabestrategien bereit:
| Framework | Aktionsausgabe | Referenz |
|---|---|---|
| Qwen-FAST | Kodiert Aktionen als diskrete Tokens, die vom Sprachmodell vorhergesagt werden | pi0-FAST |
| Qwen-OFT | MLP-Kopf nach der VLM-Ausgabe, direkte Regression kontinuierlicher Aktionswerte | OpenVLA-OFT |
| Qwen-PI | Flow-Matching (diffusionsbasierte) Methode zur Erzeugung kontinuierlicher Aktionen | pi0 |
| Qwen-GR00T | Duales System: VLM fuer High-Level-Reasoning + DiT fuer schnelle Aktionsgenerierung | GR00T-N1 |
Modularitaet bedeutet: Sie muessen lediglich Ihre Modellstruktur in einem Framework definieren und koennen den gemeinsamen Trainer, Dataloader und die Evaluations-/Deployment-Pipeline wiederverwenden — ohne Trainingsschleifen oder Evaluationscode neu schreiben zu muessen.
Trainingsstrategien
Abschnitt betitelt „Trainingsstrategien“- Einzelaufgaben-Imitationslernen (Lernen aus menschlichen Demonstrationen — keine Belohnungsfunktion erforderlich).
- Multimodales Multi-Task-Co-Training (gleichzeitiges Training auf mehreren Datenquellen, um zu verhindern, dass das Modell zuvor erlernte Faehigkeiten vergisst).
- [Geplant] Anpassung durch Reinforcement Learning.
Simulations-Benchmarks
Abschnitt betitelt „Simulations-Benchmarks“Unterstuetzte oder geplante Benchmarks:
- Unterstuetzt: SimplerEnv, LIBERO, RoboCasa, RoboTwin, CALVIN, BEHAVIOR.
- Geplant: SO101, RLBench.
Ausgewaehlte Benchmark-Ergebnisse
Abschnitt betitelt „Ausgewaehlte Benchmark-Ergebnisse“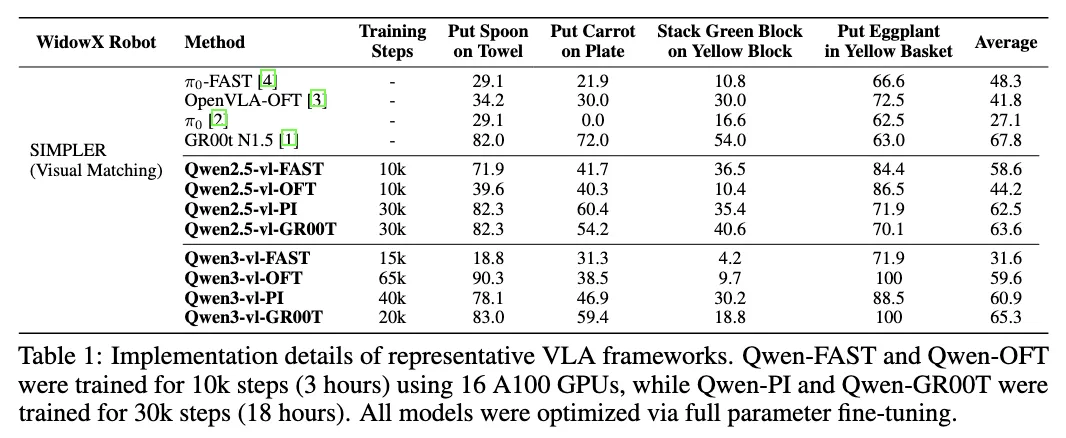
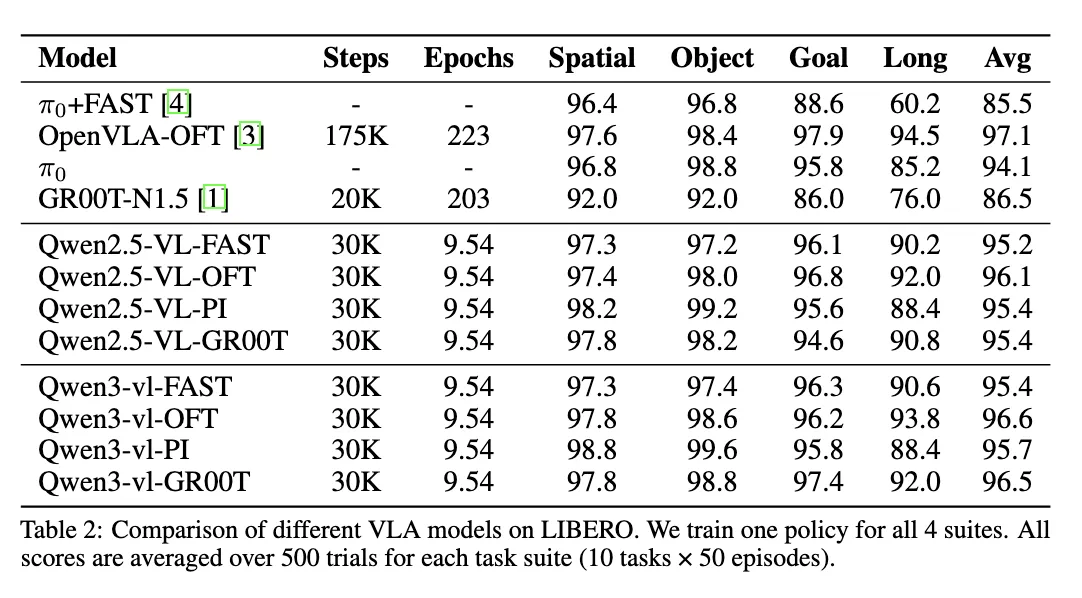
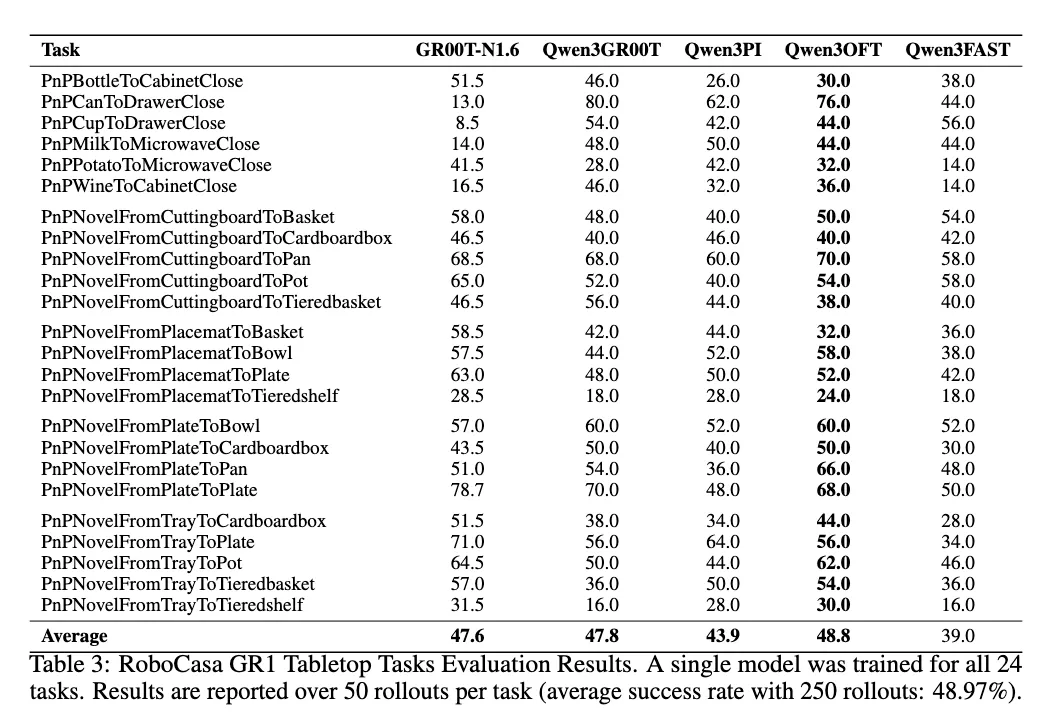
Ergebnisse & Berichte
Abschnitt betitelt „Ergebnisse & Berichte“- Technischer Bericht: StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing (arXiv:2604.05014).
- Live-Overleaf-Bericht: ein staendig aktualisiertes experimentelles Berichts-PDF mit den neuesten Benchmark-Daten und Analysen — https://www.overleaf.com/read/qqtwrnprctkf#d5bdce
Naechste Schritte
Abschnitt betitelt „Naechste Schritte“- Richten Sie Ihre Umgebung ein und ueberpruefen Sie die Installation unter Schnellstart.
- Erkunden Sie die Designprinzipien unter Baukastenprinzip.
- Durchsuchen Sie Checkpoints im Model Zoo.
Community & Links
Abschnitt betitelt „Community & Links“- Hugging Face: https://huggingface.co/StarVLA
- WeChat-Gruppe: https://github.com/starVLA/starVLA/issues/64#issuecomment-3715403845
Auf StarVLA basierende Projekte:
- NeuroVLA: A Brain-like Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
- PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
- TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Neueste Aktualisierungen
- 2025/12/25: Pipelines fuer Behavior-1K, RoboTwin 2.0 und CALVIN erstellt; Baselines sollen mit der Community geteilt werden.
- 2025/12/25: RoboCasa-Evaluationsunterstuetzung veroeffentlicht, SOTA ohne Vortraining erreicht. Siehe die RoboCasa-Dokumentation.
- 2025/12/15: Release-Regressionspruefung abgeschlossen; laufende Aktualisierungen im Taeglichen Entwicklungsprotokoll.
- 2025/12/09: Open-Source-Training fuer VLM, VLA und VLA+VLM-Co-Training. Siehe die VLM-Co-Training-Dokumentation.
- 2025/11/12: Florence-2-Unterstuetzung fuer ressourcenbeschraenktes VLM-Training (einzelne A100) hinzugefuegt. Siehe Baukastenprinzip fuer Workflow-Hinweise.
- 2025/10/30: LIBERO-Trainings- und Evaluationsleitfaeden veroeffentlicht.
- 2025/10/25: Skript-Links und Pakete basierend auf Community-Feedback verbessert.