Marco de Evaluación
Descripción General
Sección titulada «Descripción General»StarVLA estandariza el pipeline de inferencia para evaluaciones en robots reales o simulaciones mediante la transmisión de datos a través de WebSocket (un protocolo de red que permite comunicación bidireccional en tiempo real entre cliente y servidor), permitiendo que nuevos modelos se integren en entornos de evaluación existentes con cambios mínimos.
Arquitectura
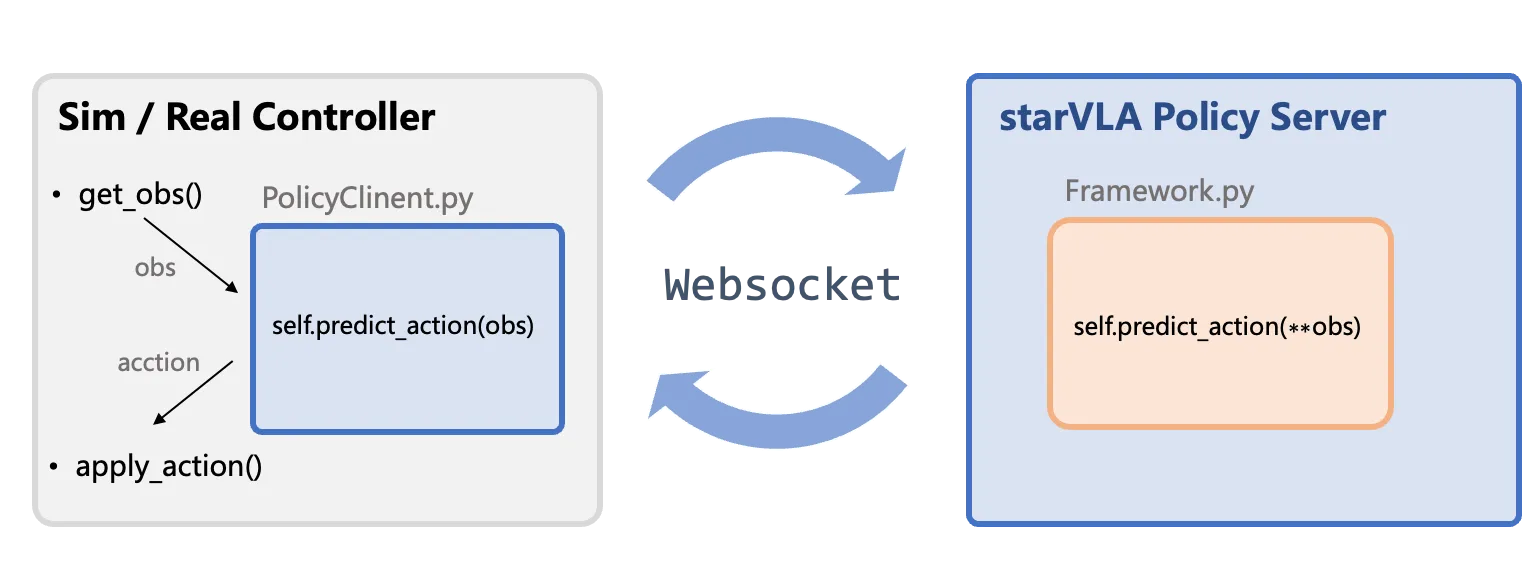
Sección titulada «Arquitectura»El framework de StarVLA utiliza una arquitectura cliente-servidor para separar el entorno de evaluación/despliegue (cliente) del servidor de políticas (inferencia del modelo).
- Servidor de Políticas: Carga el modelo, recibe observaciones y genera acciones normalizadas.
- Cliente: Interfaz con el simulador o robot real, y post-procesa las salidas del modelo:
- Desnormalización: Convierte las acciones normalizadas del modelo [-1, 1] de vuelta a cantidades físicas (por ejemplo, ángulos articulares).
- Delta a Absoluto: Si el modelo genera acciones incrementales relativas a la posición actual, las suma al estado actual para obtener posiciones objetivo absolutas.
- Ensamble de Acciones: El modelo puede predecir múltiples pasos futuros a la vez; las predicciones superpuestas de llamadas consecutivas se promedian con ponderación para una ejecución más suave.
Descripción de Componentes
Sección titulada «Descripción de Componentes»| Componente | Descripción |
|---|---|
| Sim / Real Controller | Externo a StarVLA: Contiene el bucle principal del entorno de evaluación o controlador del robot, manejando la recolección de observaciones (get_obs()) y la ejecución de acciones (apply_action()). |
| PolicyClient.py & WebSocket & PolicyServer | Flujo de Comunicación Estándar: Wrapper del lado del cliente responsable de la transmisión de datos (tunneling) e interfaz entre el entorno y el servidor. |
| Framework.py | Núcleo de Inferencia del Modelo: Contiene la función de inferencia del modelo definida por el usuario (Framework.predict_action), que es la lógica principal para generar acciones. |
Protocolo de Datos
Sección titulada «Protocolo de Datos»Ejemplo mínimo en pseudo-código (cliente del lado de evaluación):
# Ruta de importación: from deployment.policy_client.policy_client import WebsocketClientPolicyimport WebsocketClientPolicy
client = WebsocketClientPolicy( host="127.0.0.1", port=10092)
while True: images = capture_multiview() # devuelve List[np.ndarray] lang = get_instruction() # puede venir de scripts de tareas example = { "image": images, "lang": lang, }
result = client.predict_action(example) # --> reenviado a framework.predict_action action = result["normalized_actions"][0] # tomar el primer elemento del batch apply_action(action)Para el Servidor del Modelo, simplemente inícialo con:
#!/bin/bashexport PYTHONPATH=$(pwd):${PYTHONPATH}
# Apunta a tu Python de conda de StarVLA# $(which python) selecciona automáticamente el Python de tu entorno conda actualmente activado# Asegúrate de haber ejecutado `conda activate starVLA` antes de ejecutar este scriptexport star_vla_python=$(which python)your_ckpt=results/Checkpoints/xxx.pt # Reemplaza con la ruta de tu checkpointgpu_id=0port=5694
# export DEBUG=trueCUDA_VISIBLE_DEVICES=$gpu_id ${star_vla_python} deployment/model_server/server_policy.py \ --ckpt_path ${your_ckpt} \ --port ${port} \ --use_bf16- Asegúrate de que cada campo en
examplesea serializable a JSON o convertible (listas, flotantes, enteros, cadenas); convierte objetos personalizados explícitamente. - Las imágenes deben enviarse como
np.ndarray. Realiza la conversiónPIL.Image -> np.ndarrayantes de la transmisión y convierte de vuelta en el servidor usandoto_pil_preserve(from starVLA.model.utils import to_pil_preserve) si es necesario. - Mantén los metadatos auxiliares (IDs de episodio, marcas de tiempo, etc.) en claves dedicadas para que el framework pueda reenviarlos o registrarlos sin colisiones.
Diseño de la Interfaz PolicyClient
Sección titulada «Diseño de la Interfaz PolicyClient»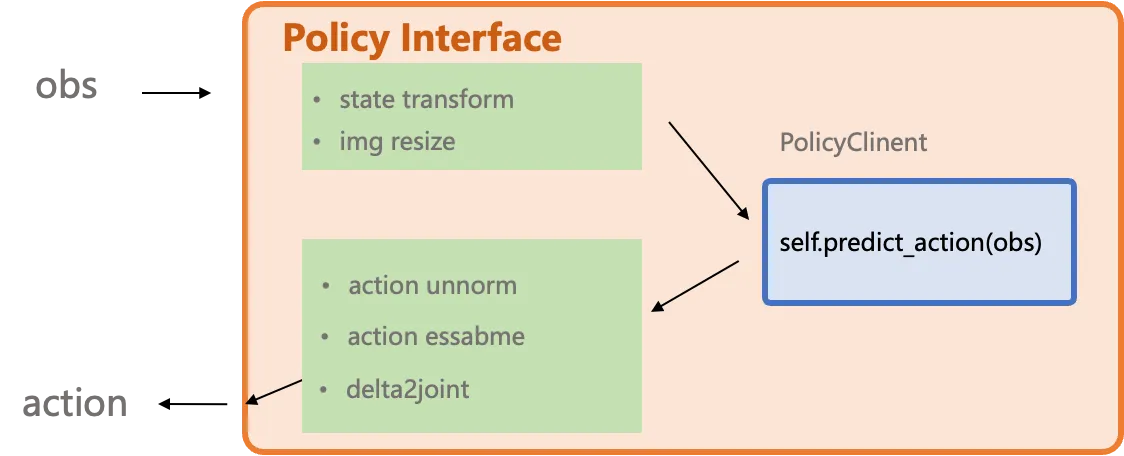
La interfaz *2model_interface.py está diseñada para envolver y abstraer cualquier variación que provenga del entorno de simulación o del mundo real. También soporta controladores definidos por el usuario, como convertir acciones delta a posiciones articulares absolutas. Puedes consultar las implementaciones para diferentes benchmarks en examples para construir tu propio despliegue.
Preguntas Frecuentes
Sección titulada «Preguntas Frecuentes»P: ¿Por qué los ejemplos contienen archivos como model2{bench}_client.py?
R: Encapsulan la alineación específica del benchmark, por ejemplo, ensamble de acciones, conversión de acciones delta a acciones absolutas, o manejo de particularidades del simulador, para que el servidor del modelo pueda mantenerse genérico.
P: ¿Por qué el modelo espera imágenes PIL mientras el transporte usa ndarray?
R: Los payloads de WebSocket no serializan objetos PIL directamente. Convierte a np.ndarray del lado del cliente y restaura a PIL dentro del framework si el modelo lo requiere.
Los comentarios sobre necesidades específicas del entorno son bienvenidos a través de issues.