Descripción del Proyecto
StarVLA es una base de código modular tipo lego para desarrollar Modelos de Visión-Lenguaje (VLMs) en modelos de Visión-Lenguaje-Acción (VLA).
En resumen: los VLMs comprenden imágenes y texto; los VLAs además generan acciones de robot. StarVLA maneja esta transformación de extremo a extremo — desde la preparación de datos y el entrenamiento del modelo hasta la evaluación en simulación — con componentes que son depurables de forma independiente y plug-and-play.
Características Principales
Sección titulada «Características Principales»Frameworks VLA
Sección titulada «Frameworks VLA»StarVLA proporciona oficialmente la familia de modelos StarVLA basada en Qwen-VL con 4 estrategias diferentes de salida de acciones:
| Framework | Salida de Acción | Referencia |
|---|---|---|
| Qwen-FAST | Codifica acciones como tokens discretos predichos por el modelo de lenguaje | pi0-FAST |
| Qwen-OFT | Cabeza MLP después de la salida del VLM, regresando directamente valores continuos de acción | OpenVLA-OFT |
| Qwen-PI | Método de Flow-Matching (basado en difusión) para generar acciones continuas | pi0 |
| Qwen-GR00T | Sistema dual: VLM para razonamiento de alto nivel + DiT para generación rápida de acciones | GR00T-N1 |
La modularidad significa: solo necesitas definir la estructura de tu modelo en un Framework, y puedes reutilizar el Trainer, Dataloader y pipeline de evaluación/despliegue compartidos — sin necesidad de reescribir bucles de entrenamiento o código de evaluación.
Estrategias de Entrenamiento
Sección titulada «Estrategias de Entrenamiento»- Aprendizaje por imitación de tarea única (aprendizaje a partir de demostraciones humanas — sin necesidad de función de recompensa).
- Co-entrenamiento multimodal y multitarea (entrenamiento con múltiples fuentes de datos simultáneamente para evitar que el modelo olvide capacidades previamente aprendidas).
- [Planificado] Adaptación con aprendizaje por refuerzo.
Benchmarks de Simulación
Sección titulada «Benchmarks de Simulación»Benchmarks soportados o planificados:
- Soportados: SimplerEnv, LIBERO, RoboCasa, RoboTwin, CALVIN, BEHAVIOR.
- Planificados: SO101, RLBench.
Resultados Seleccionados de Benchmarks
Sección titulada «Resultados Seleccionados de Benchmarks»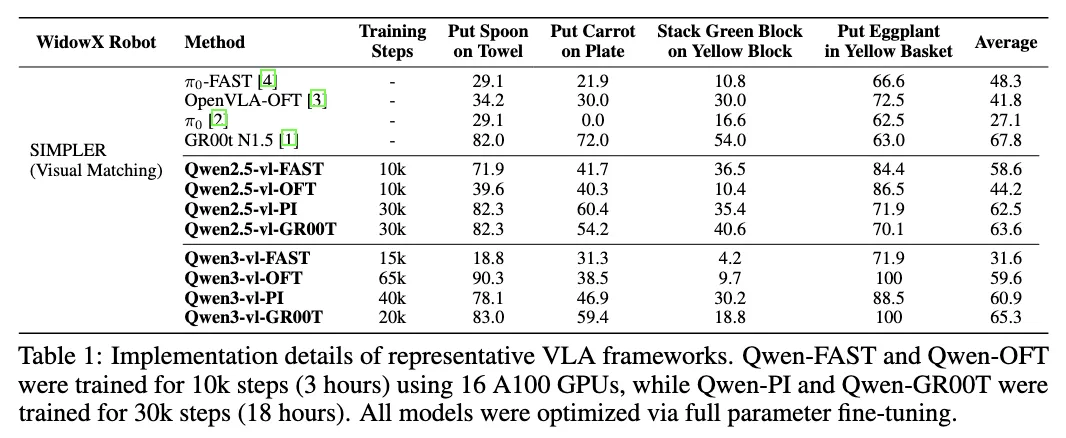
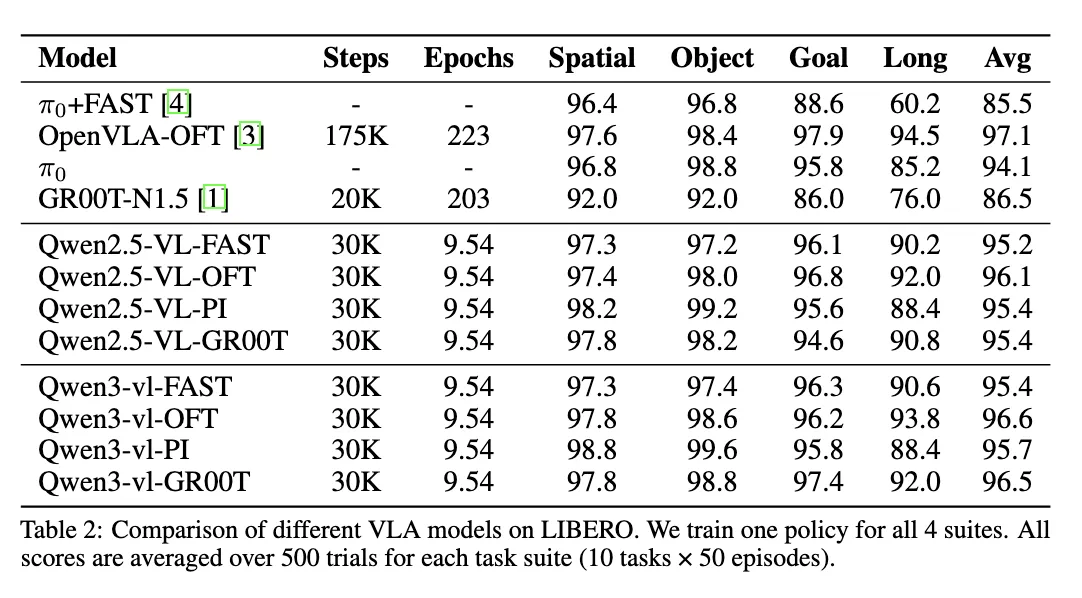
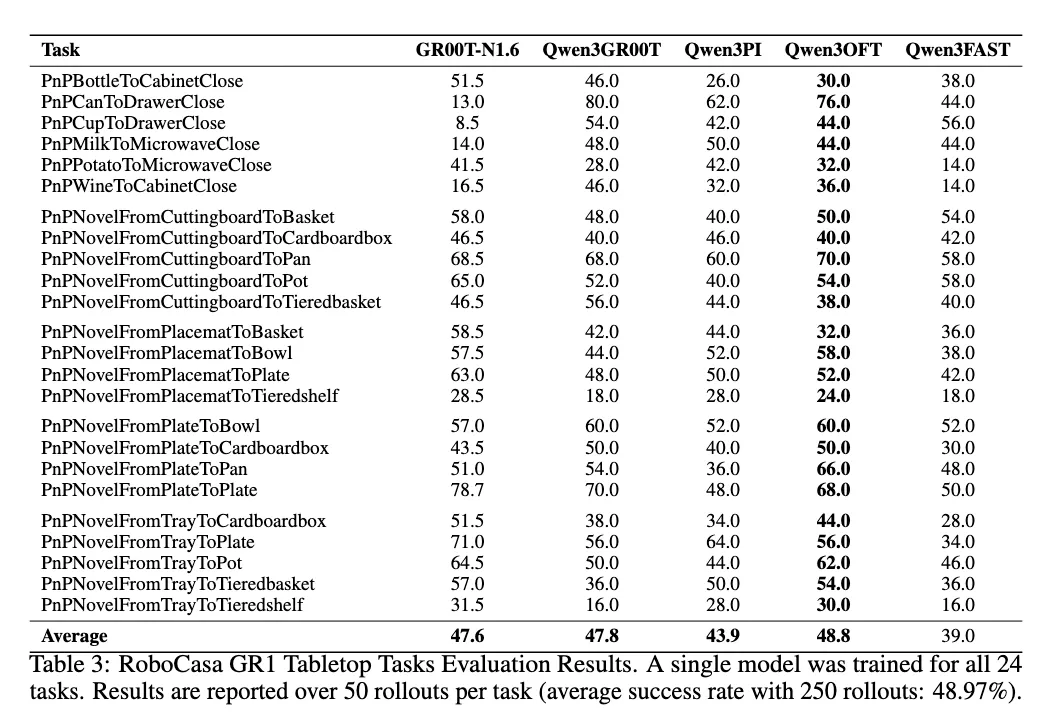
Resultados e Informes
Sección titulada «Resultados e Informes»- Informe técnico: StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing (arXiv:2604.05014).
- Informe en vivo de Overleaf: un PDF de informe experimental actualizado continuamente con los últimos datos y análisis de benchmarks — https://www.overleaf.com/read/qqtwrnprctkf#d5bdce
Próximos Pasos
Sección titulada «Próximos Pasos»- Configura tu entorno y verifica la instalación en Inicio Rápido.
- Explora los principios de diseño en Diseño Tipo Lego.
- Consulta los checkpoints en Catálogo de Modelos.
Comunidad y Enlaces
Sección titulada «Comunidad y Enlaces»- Hugging Face: https://huggingface.co/StarVLA
- Grupo de WeChat: https://github.com/starVLA/starVLA/issues/64#issuecomment-3715403845
Proyectos Basados en StarVLA:
- NeuroVLA: A Brain-like Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
- PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
- TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Últimas Actualizaciones
- 2025/12/25: Pipelines establecidos para Behavior-1K, RoboTwin 2.0 y CALVIN; buscamos compartir líneas base con la comunidad.
- 2025/12/25: Soporte de evaluación de RoboCasa publicado, logrando SOTA sin pre-entrenamiento. Consulta la documentación de RoboCasa.
- 2025/12/15: Verificación de regresión del release completada; actualizaciones continuas en el Registro Diario de Desarrollo.
- 2025/12/09: Entrenamiento open-source para VLM, VLA y co-entrenamiento VLA+VLM. Consulta la documentación de co-entrenamiento VLM.
- 2025/11/12: Soporte para Florence-2 añadido para entrenamiento VLM con recursos limitados (una sola A100). Consulta Diseño Tipo Lego para notas del flujo de trabajo.
- 2025/10/30: Guías de entrenamiento y evaluación de LIBERO publicadas.
- 2025/10/25: Enlaces de scripts y empaquetado mejorados según retroalimentación de la comunidad.