Framework d'evaluation
Vue d’ensemble
Section intitulée « Vue d’ensemble »StarVLA standardise le pipeline d’inference pour les evaluations en robot reel ou en simulation en acheminant les donnees via WebSocket (un protocole reseau qui permet une communication bidirectionnelle en temps reel entre client et serveur), permettant d’integrer de nouveaux modeles dans les environnements d’evaluation existants avec un minimum de modifications.
Architecture
Section intitulée « Architecture »Le framework StarVLA utilise une architecture client-serveur pour separer l’environnement d’evaluation/deploiement (client) du serveur de politique (inference du modele).
- Serveur de politique : Charge le modele, recoit les observations et produit des actions normalisees.
- Client : Interface avec le simulateur ou le robot reel, et post-traite les sorties du modele :
- Denormalisation : Convertit les actions normalisees [-1, 1] du modele en grandeurs physiques (par exemple, angles articulaires).
- Delta vers absolu : Si le modele produit des actions incrementales par rapport a la position actuelle, les ajoute a l’etat courant pour obtenir les positions cibles absolues.
- Ensemble d’actions : Le modele peut predire plusieurs etapes futures a la fois ; les predictions chevauchantes issues d’appels consecutifs sont moyennees ponderees pour une execution plus fluide.
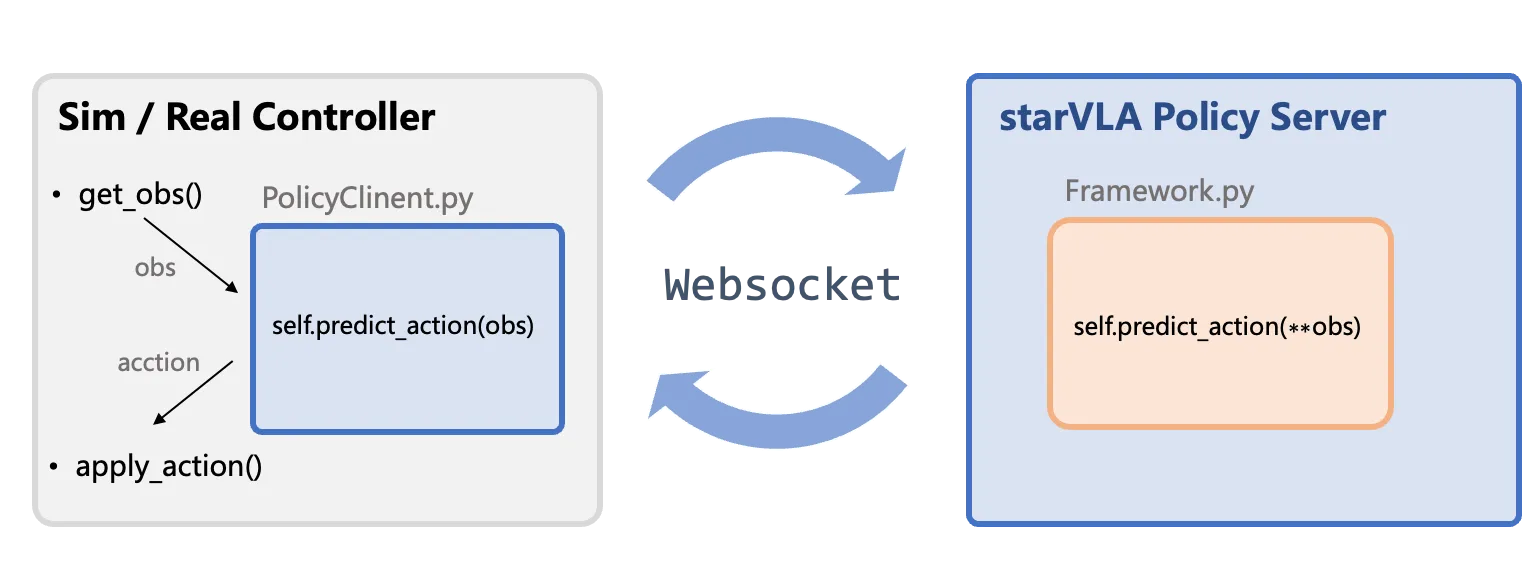
Description des composants
Section intitulée « Description des composants »| Composant | Description |
|---|---|
| Sim / Real Controller | Externe a StarVLA : Contient la boucle principale de l’environnement d’evaluation ou du controleur du robot, gerant la collecte des observations (get_obs()) et l’execution des actions (apply_action()). |
| PolicyClient.py & WebSocket & PolicyServer | Flux de communication standard : Wrapper cote client responsable de la transmission des donnees (acheminement) et de l’interface entre l’environnement et le serveur. |
| Framework.py | Coeur d’inference du modele : Contient la fonction d’inference du modele definie par l’utilisateur (Framework.predict_action), qui est la logique principale pour la generation d’actions. |
Protocole de donnees
Section intitulée « Protocole de donnees »Exemple minimal en pseudo-code (client cote evaluation) :
# Chemin d'import : from deployment.policy_client.policy_client import WebsocketClientPolicyimport WebsocketClientPolicy
client = WebsocketClientPolicy( host="127.0.0.1", port=10092)
while True: images = capture_multiview() # retourne List[np.ndarray] lang = get_instruction() # peut provenir des scripts de taches example = { "image": images, "lang": lang, }
result = client.predict_action(example) # --> transmis a framework.predict_action action = result["normalized_actions"][0] # prendre le premier element du batch apply_action(action)Pour le serveur de modele, lancez-le simplement avec :
#!/bin/bashexport PYTHONPATH=$(pwd):${PYTHONPATH}
# Pointer vers le Python conda de votre StarVLA# $(which python) recupere automatiquement le Python de votre env conda active# Assurez-vous d'avoir execute `conda activate starVLA` avant d'executer ce scriptexport star_vla_python=$(which python)your_ckpt=results/Checkpoints/xxx.pt # Remplacez par le chemin de votre checkpointgpu_id=0port=5694
# export DEBUG=trueCUDA_VISIBLE_DEVICES=$gpu_id ${star_vla_python} deployment/model_server/server_policy.py \ --ckpt_path ${your_ckpt} \ --port ${port} \ --use_bf16- Assurez-vous que chaque champ dans
exampleest serialisable en JSON ou convertible (listes, flottants, entiers, chaines de caracteres) ; convertissez explicitement les objets personnalises. - Les images doivent etre envoyees sous forme de
np.ndarray. Effectuez la conversionPIL.Image -> np.ndarrayavant la transmission et reconvertissez cote serveur en utilisantto_pil_preserve(from starVLA.model.utils import to_pil_preserve) si necessaire. - Conservez les metadonnees auxiliaires (identifiants d’episodes, horodatages, etc.) dans des cles dediees pour que le framework puisse les transmettre ou les journaliser sans conflit.
Conception de l’interface PolicyClient
Section intitulée « Conception de l’interface PolicyClient »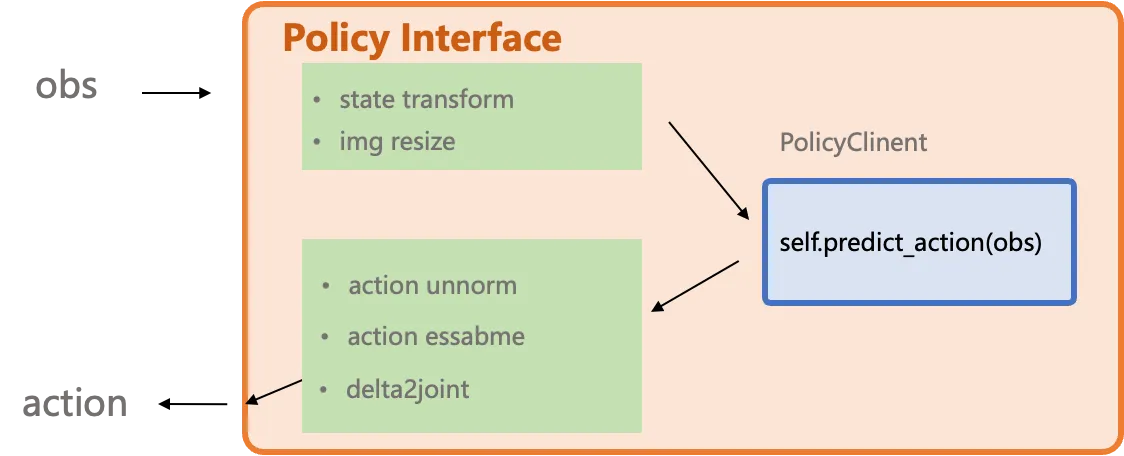
L’interface *2model_interface.py est concue pour encapsuler et abstraire toutes les variations provenant de l’environnement de simulation ou du monde reel. Elle prend egalement en charge des controleurs definis par l’utilisateur, comme la conversion d’actions delta en positions articulaires absolues. Vous pouvez vous referer aux implementations pour differents benchmarks dans examples pour construire votre propre deploiement.
Q : Pourquoi les exemples contiennent-ils des fichiers tels que model2{bench}_client.py ?
R : Ils encapsulent l’alignement specifique au benchmark, par exemple l’assemblage d’actions, la conversion d’actions delta en actions absolues, ou la gestion des particularites du simulateur, afin que le serveur de modele puisse rester generique.
Q : Pourquoi le modele attend-il des images PIL alors que le transport utilise ndarray ?
R : Les payloads WebSocket ne serialisent pas directement les objets PIL. Convertissez en np.ndarray cote client et restaurez en PIL dans le framework si le modele le requiert.
N’hesitez pas a nous faire part de vos besoins specifiques a votre environnement via les issues.