Vue d'ensemble du projet
StarVLA est un codebase modulaire, de type LEGO, pour transformer des modeles de Vision-Langage (VLM) en modeles de Vision-Langage-Action (VLA).
En bref : les VLM comprennent les images et le texte ; les VLA produisent en plus des actions robotiques. StarVLA gere cette transformation de bout en bout — de la preparation des donnees et l’entrainement du modele a l’evaluation en simulation — avec des composants independamment debuggables et interchangeables.
Fonctionnalites cles
Section intitulée « Fonctionnalites cles »Frameworks VLA
Section intitulée « Frameworks VLA »StarVLA fournit officiellement la famille de modeles StarVLA basee sur Qwen-VL avec 4 strategies differentes de sortie d’actions :
| Framework | Sortie d’action | Reference |
|---|---|---|
| Qwen-FAST | Encode les actions en tokens discrets predits par le modele de langage | pi0-FAST |
| Qwen-OFT | Tete MLP apres la sortie du VLM, regression directe des valeurs d’action continues | OpenVLA-OFT |
| Qwen-PI | Methode Flow-Matching (basee sur la diffusion) pour generer des actions continues | pi0 |
| Qwen-GR00T | Systeme dual : VLM pour le raisonnement haut niveau + DiT pour la generation rapide d’actions | GR00T-N1 |
La modularite signifie : vous n’avez qu’a definir la structure de votre modele dans un Framework, et vous pouvez reutiliser le Trainer, le Dataloader et le pipeline d’evaluation/deploiement partages — pas besoin de reecrire les boucles d’entrainement ou le code d’evaluation.
Strategies d’entrainement
Section intitulée « Strategies d’entrainement »- Apprentissage par imitation sur une tache unique (apprentissage a partir de demonstrations humaines — pas de fonction de recompense necessaire).
- Co-entrainement multimodal multi-taches (entrainement sur plusieurs sources de donnees simultanement pour empecher le modele d’oublier les competences precedemment acquises).
- [Prevu] Adaptation par apprentissage par renforcement.
Benchmarks de simulation
Section intitulée « Benchmarks de simulation »Benchmarks pris en charge ou prevus :
- Pris en charge : SimplerEnv, LIBERO, RoboCasa, RoboTwin, CALVIN, BEHAVIOR.
- Prevus : SO101, RLBench.
Resultats de benchmarks selectionnes
Section intitulée « Resultats de benchmarks selectionnes »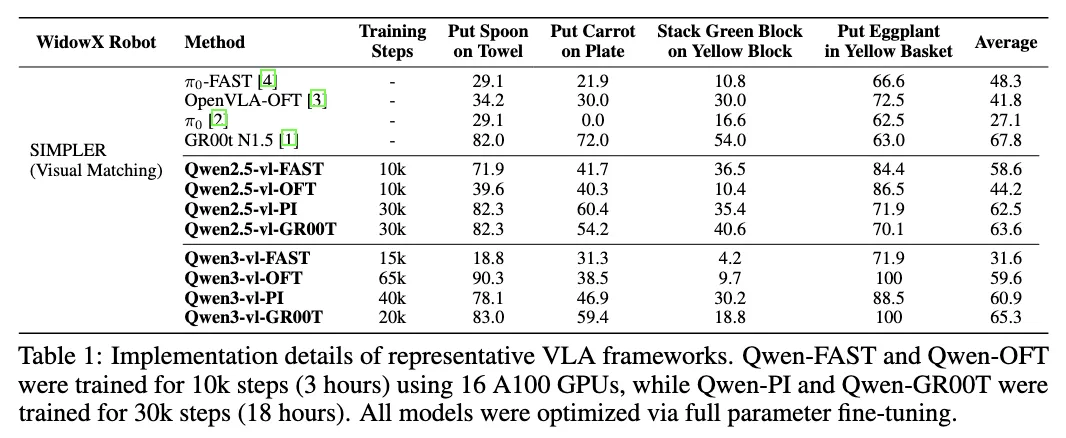
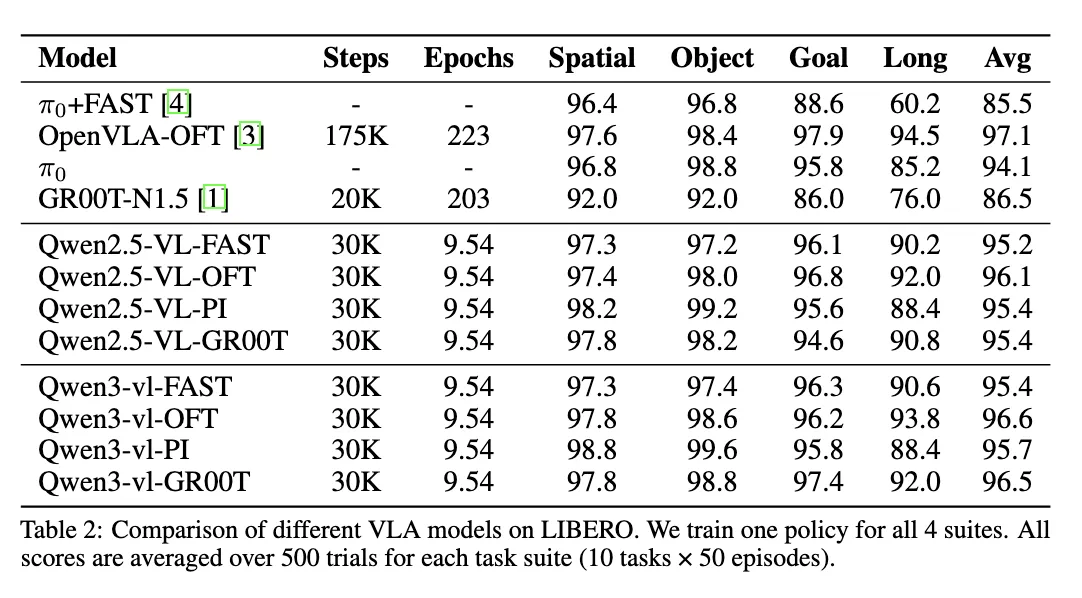
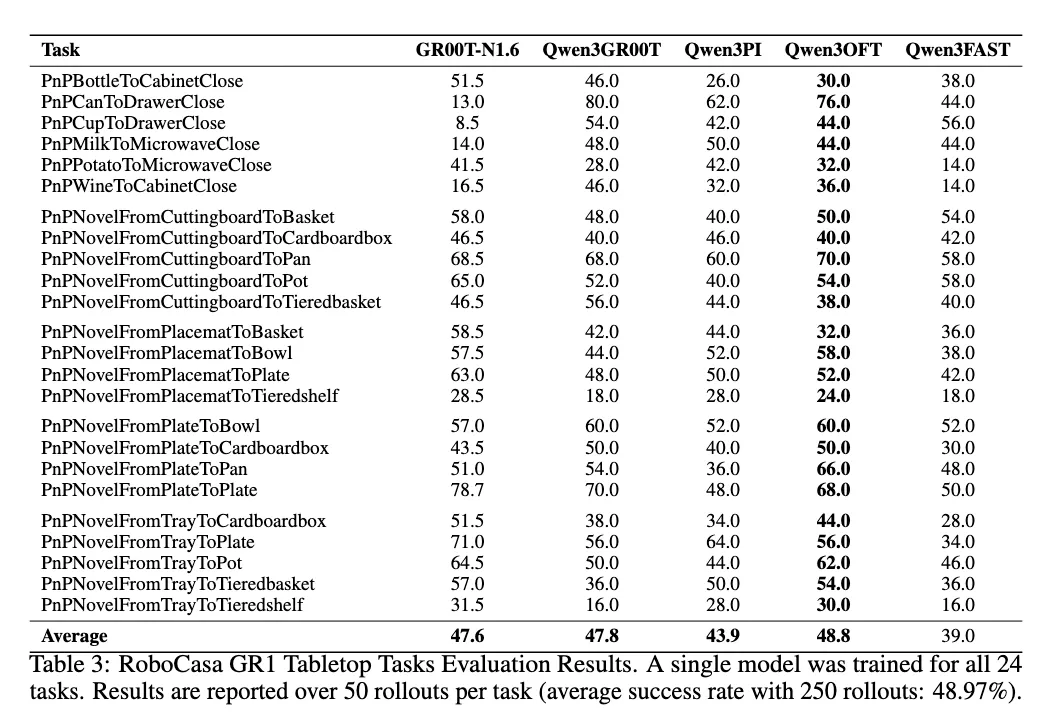
Resultats et rapports
Section intitulée « Resultats et rapports »- Rapport technique : StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing (arXiv:2604.05014).
- Rapport Overleaf en direct : un rapport PDF experimental mis a jour en continu avec les dernieres donnees de benchmark et analyses — https://www.overleaf.com/read/qqtwrnprctkf#d5bdce
Quelle est la suite ?
Section intitulée « Quelle est la suite ? »- Configurez votre environnement et verifiez l’installation dans le Demarrage rapide.
- Explorez les principes de conception dans la Conception modulaire.
- Parcourez les checkpoints dans le Model Zoo.
Communaute et liens
Section intitulée « Communaute et liens »- Hugging Face : https://huggingface.co/StarVLA
- Groupe WeChat : https://github.com/starVLA/starVLA/issues/64#issuecomment-3715403845
Projets bases sur StarVLA :
- NeuroVLA : A Brain-like Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
- PhysBrain : Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
- TwinBrainVLA : Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- LangForce : Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Dernieres mises a jour
- 2025/12/25 : Pipelines etablis pour Behavior-1K, RoboTwin 2.0 et CALVIN ; nous cherchons a partager les baselines avec la communaute.
- 2025/12/25 : Support d’evaluation RoboCasa publie, atteignant le SOTA sans pre-entrainement. Voir la documentation RoboCasa.
- 2025/12/15 : Verification de regression de la release terminee ; mises a jour en cours dans le Journal de developpement quotidien.
- 2025/12/09 : Entrainement open-source pour VLM, VLA et co-entrainement VLA+VLM. Voir la documentation du co-entrainement VLM.
- 2025/11/12 : Support de Florence-2 ajoute pour l’entrainement VLM avec des ressources limitees (un seul A100). Voir Conception modulaire pour les notes de workflow.
- 2025/10/30 : Guides d’entrainement et d’evaluation LIBERO publies.
- 2025/10/25 : Liens vers les scripts et packaging ameliores suite aux retours de la communaute.