项目概览
StarVLA 是一个”乐高式”的模块化代码库,用于把视觉-语言模型(VLM) 发展为视觉-语言-动作模型(VLA)。
简单来说:VLM 能理解图像和文字,VLA 在此基础上还能输出机器人动作。StarVLA 帮你完成这个转化过程——从数据准备、模型训练到仿真评测,各组件独立可调试、即插即用。
VLA 框架
Section titled “VLA 框架”StarVLA 官方提供了基于 Qwen-VL 的 StarVLA Model Family,包含 4 种不同的动作输出方式:
| 框架 | 动作输出方式 | 参考论文 |
|---|---|---|
| Qwen-FAST | 将动作编码为离散 token,由语言模型直接预测 | pi0-FAST |
| Qwen-OFT | 在 VLM 输出后接一个 MLP 头,直接回归连续动作值 | OpenVLA-OFT |
| Qwen-PI | 使用 Flow-Matching(扩散式)方法生成连续动作 | pi0 |
| Qwen-GR00T | 双系统架构:VLM 做高层推理 + DiT 做快速动作生成 | GR00T-N1 |
模块化意味着:你只需在 Framework 中定义自己的模型结构,就可以复用通用的 Trainer、Dataloader 和评测部署管线——无需重写训练循环或评测代码。
- 单任务模仿学习(从人类演示数据中学习,不需要设计奖励函数)。
- 多模态多任务协同训练(同时使用多种数据训练,防止模型在学习新任务时遗忘已掌握的能力)。
- [计划中] 强化学习适配。
已支持或计划支持的基准:
- 已支持:SimplerEnv、LIBERO、RoboCasa、RoboTwin、CALVIN、BEHAVIOR。
- 规划中:SO101、RLBench。
部分 Benchmark 测试结果
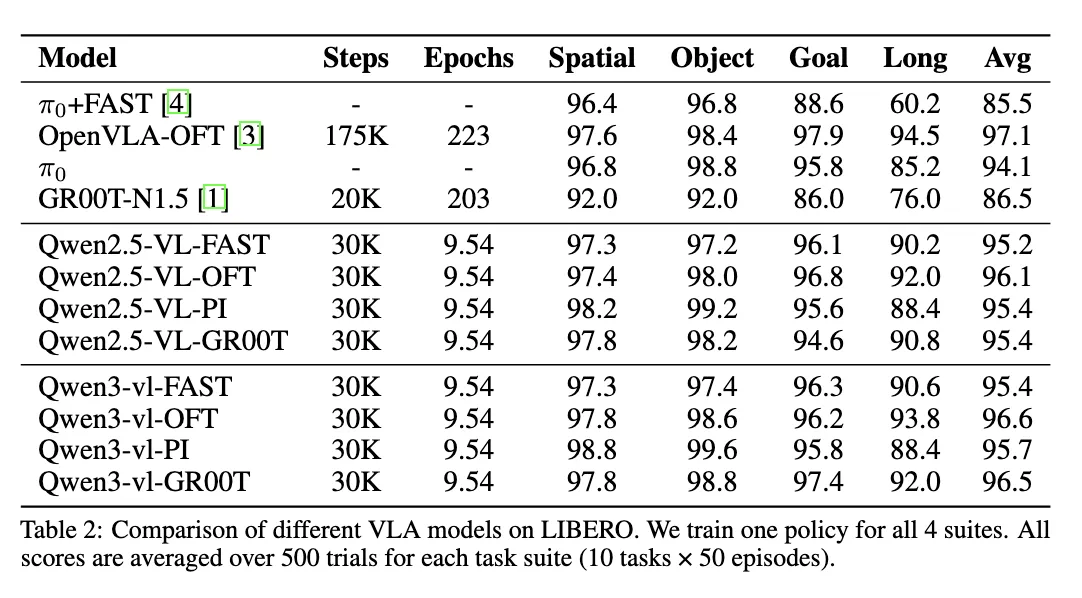
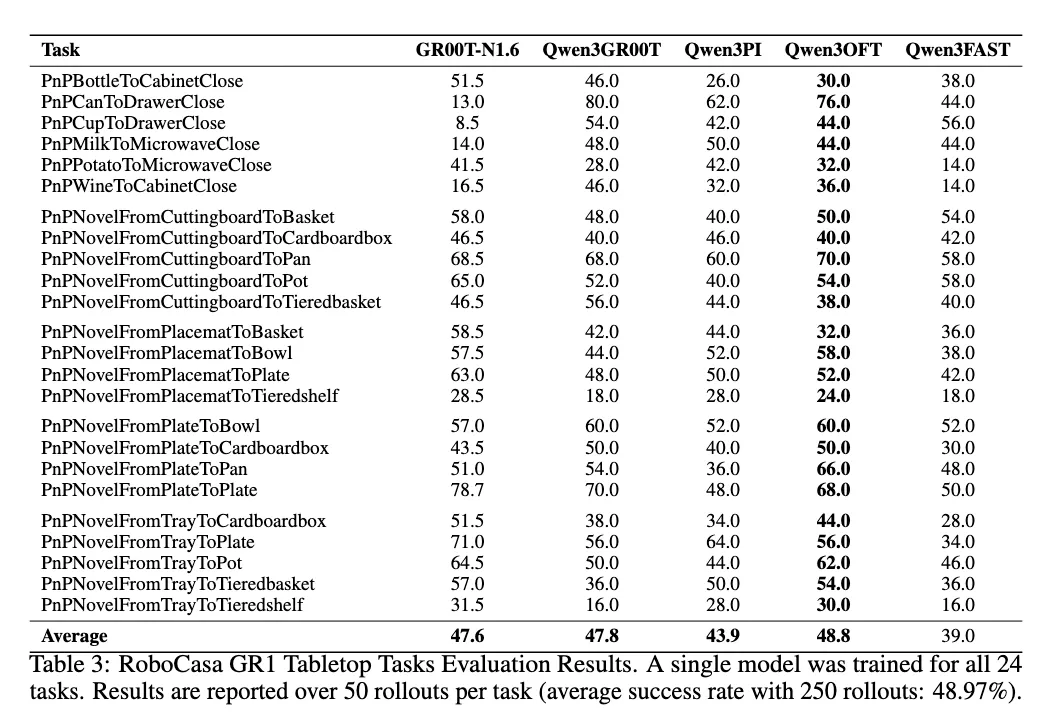
Section titled “部分 Benchmark 测试结果”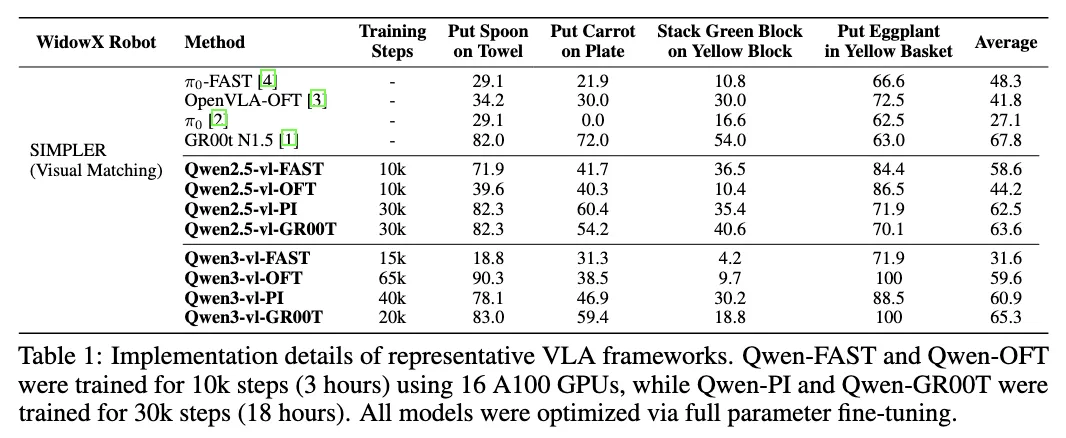
- 技术报告:StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing(arXiv:2604.05014)。
- Overleaf 实时报告:持续更新的实验报告 PDF,包含最新基准测试数据与分析 —— https://www.overleaf.com/read/qqtwrnprctkf#d5bdce
- Hugging Face:https://huggingface.co/StarVLA
- 微信群:https://github.com/starVLA/starVLA/issues/64#issuecomment-3715403845
基于 StarVLA 的项目:
- NeuroVLA: A Brain-like Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
- PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
- TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
最新动态
- 2025/12/25:建立 Behavior-1K、RoboTwin 2.0 与 CALVIN 的流水线,期待与社区共享基线。
- 2025/12/25:发布 RoboCasa 评测支持,无预训练即可达到 SOTA,详见 RoboCasa 文档。
- 2025/12/15:完成回归测试,持续更新见 Daily Development Log。
- 2025/12/09:支持训练 VLM、VLA 与 VLA+VLM 协同训练,见 VLM 联合训练文档。
- 2025/11/12:新增 Florence-2 支持,可在单张 A100 上训练,详见 乐高式设计。
- 2025/10/30:发布 LIBERO 训练与评测指南。
- 2025/10/25:修复脚本链接与打包流程,感谢社区反馈。