Project Overview
Vision
Section titled “Vision”StarVLA is a lego-like, modular codebase for developing Vision-Language Models (VLMs) into Vision-Language-Action (VLA) models.
In short: VLMs understand images and text; VLAs additionally output robot actions. StarVLA handles this transformation end-to-end — from data preparation and model training to simulation evaluation — with components that are independently debuggable and plug-and-play.
Key Features
Section titled “Key Features”VLA Frameworks
Section titled “VLA Frameworks”StarVLA officially provides the Qwen-VL-based StarVLA Model Family with 4 different action output strategies:
| Framework | Action Output | Reference |
|---|---|---|
| Qwen-FAST | Encodes actions as discrete tokens predicted by the language model | pi0-FAST |
| Qwen-OFT | MLP head after VLM output, directly regressing continuous action values | OpenVLA-OFT |
| Qwen-PI | Flow-Matching (diffusion-based) method for generating continuous actions | pi0 |
| Qwen-GR00T | Dual-system: VLM for high-level reasoning + DiT for fast action generation | GR00T-N1 |
Modularity means: you only need to define your model structure in a Framework, and you can reuse the shared Trainer, Dataloader, and evaluation/deployment pipeline — no need to rewrite training loops or evaluation code.
Training Strategies
Section titled “Training Strategies”- Single-task imitation learning (learning from human demonstrations — no reward function needed).
- Multimodal multi-task co-training (training on multiple data sources simultaneously to prevent the model from forgetting previously learned capabilities).
- [Planned] Reinforcement learning adaptation.
Simulation Benchmarks
Section titled “Simulation Benchmarks”Supported or planned benchmarks:
- Supported: SimplerEnv, LIBERO, RoboCasa, RoboTwin, CALVIN, BEHAVIOR.
- Planned: SO101, RLBench.
Selected Benchmark Results
Section titled “Selected Benchmark Results”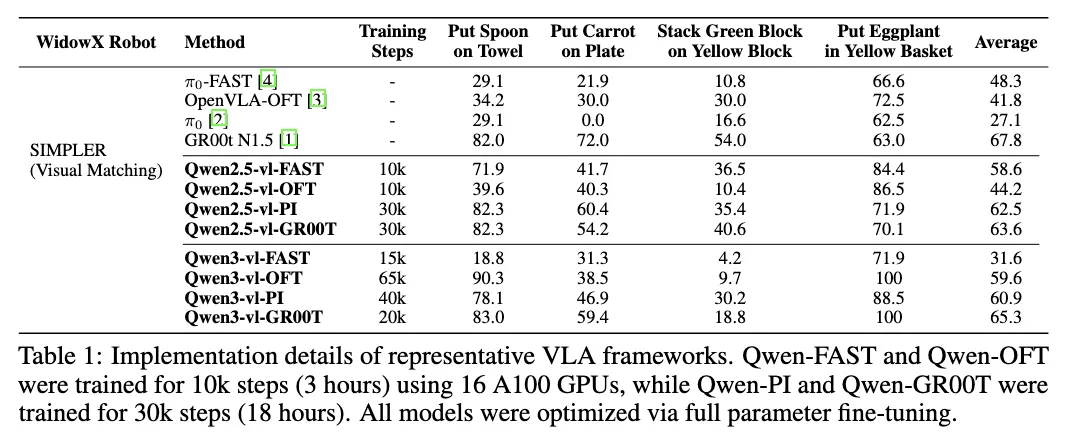
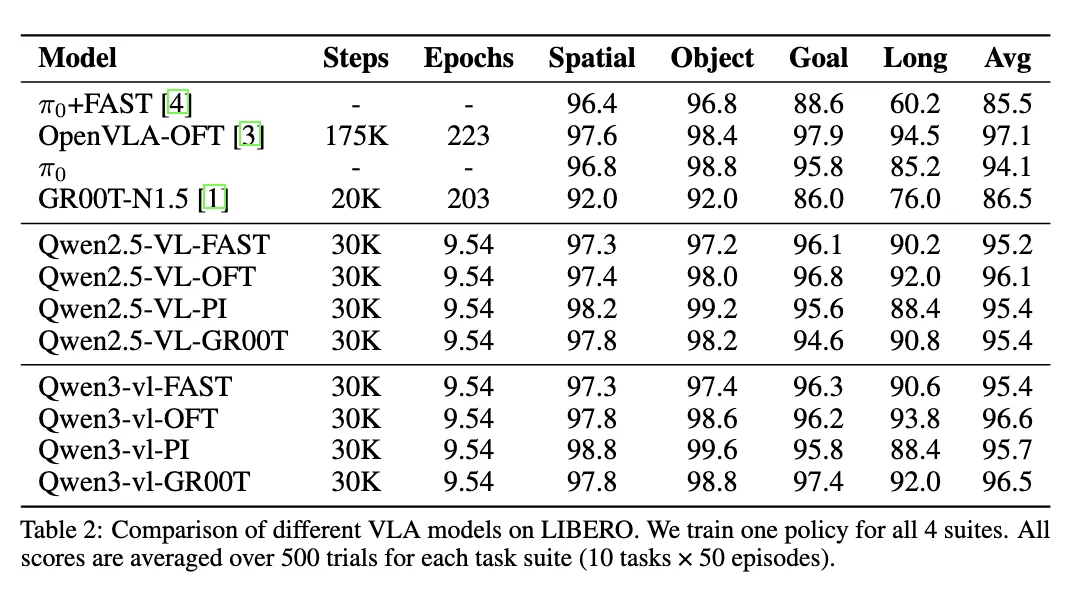
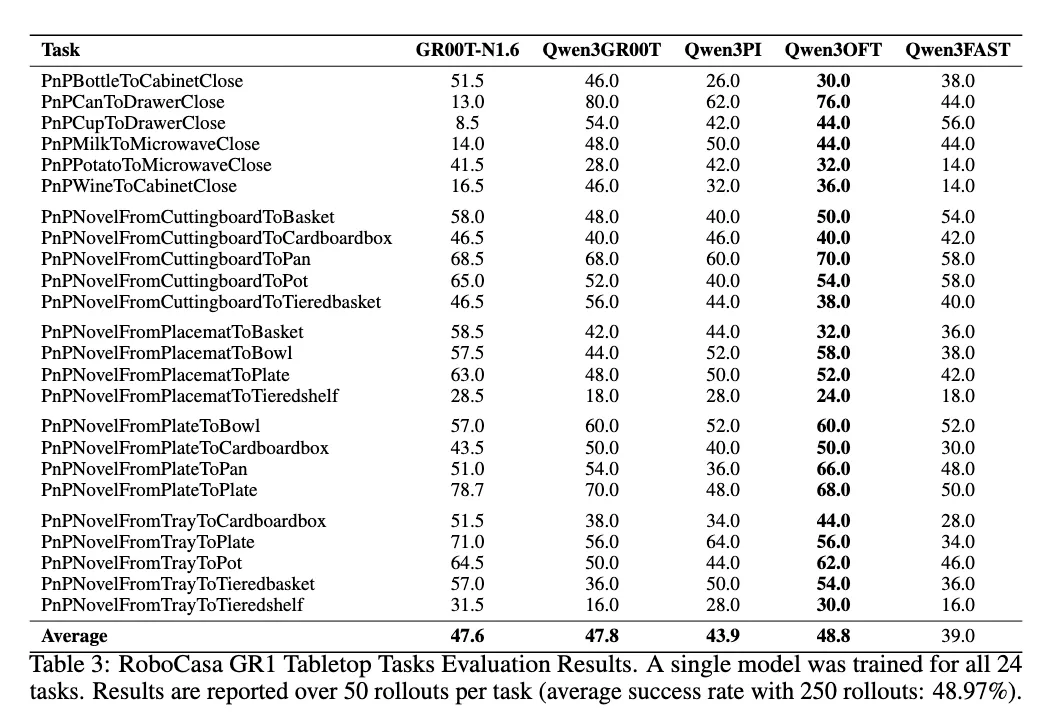
Results & Reports
Section titled “Results & Reports”Results are continuously tracked in a live Overleaf report (a continuously updated experimental report PDF with the latest benchmark data and analysis): https://www.overleaf.com/read/qqtwrnprctkf#d5bdce
Where to Go Next
Section titled “Where to Go Next”- Set up your environment and verify installation in Quick Start.
- Explore design principles in Lego-like Design.
- Browse checkpoints in Model Zoo.
Community & Links
Section titled “Community & Links”- Hugging Face: https://huggingface.co/StarVLA
- WeChat group: https://github.com/starVLA/starVLA/issues/64#issuecomment-3715403845
Projects Based on StarVLA:
- NeuroVLA: A Brain-like Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
- PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
- TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Latest Updates
- 2025/12/25: Pipelines established for Behavior-1K, RoboTwin 2.0, and CALVIN; looking to share baselines with the community.
- 2025/12/25: RoboCasa evaluation support released, achieving SOTA without pretraining. See the RoboCasa documentation.
- 2025/12/15: Release regression check completed; ongoing updates in the Daily Development Log.
- 2025/12/09: Open-source training for VLM, VLA, and VLA+VLM co-training. See the VLM co-training documentation.
- 2025/11/12: Florence-2 support added for resource-constrained VLM training (single A100). See Lego-like Design for workflow notes.
- 2025/10/30: LIBERO training and evaluation guides released.
- 2025/10/25: Script links and packaging polished based on community feedback.